
Leena Choi, PhD
Professor of Biostatistics and Biomedical Informatics
Vice Chair of Diversity and Inclusion
Department of Biostatistics
https://www.vumc.org/biostatistics/person/leena-choi-phd
The major research focus of our lab is to construct a system, called “EHR2PKPD”, for drug-related studies such as pharmacokinetics (PK), pharmacodynamics (PD), and pharmacogenomics (PGx) studies using electronic health records (EHRs). This system would allow to perform drug-related studie more efficiently by standardizing data extraction, data processing, and data building procedures. This system would provide a foundation for PK/PD-model guided clinical decision support systems embedded in EHRs to provide an optimal pharmacotherapy, the overarching goal of precision medicine.
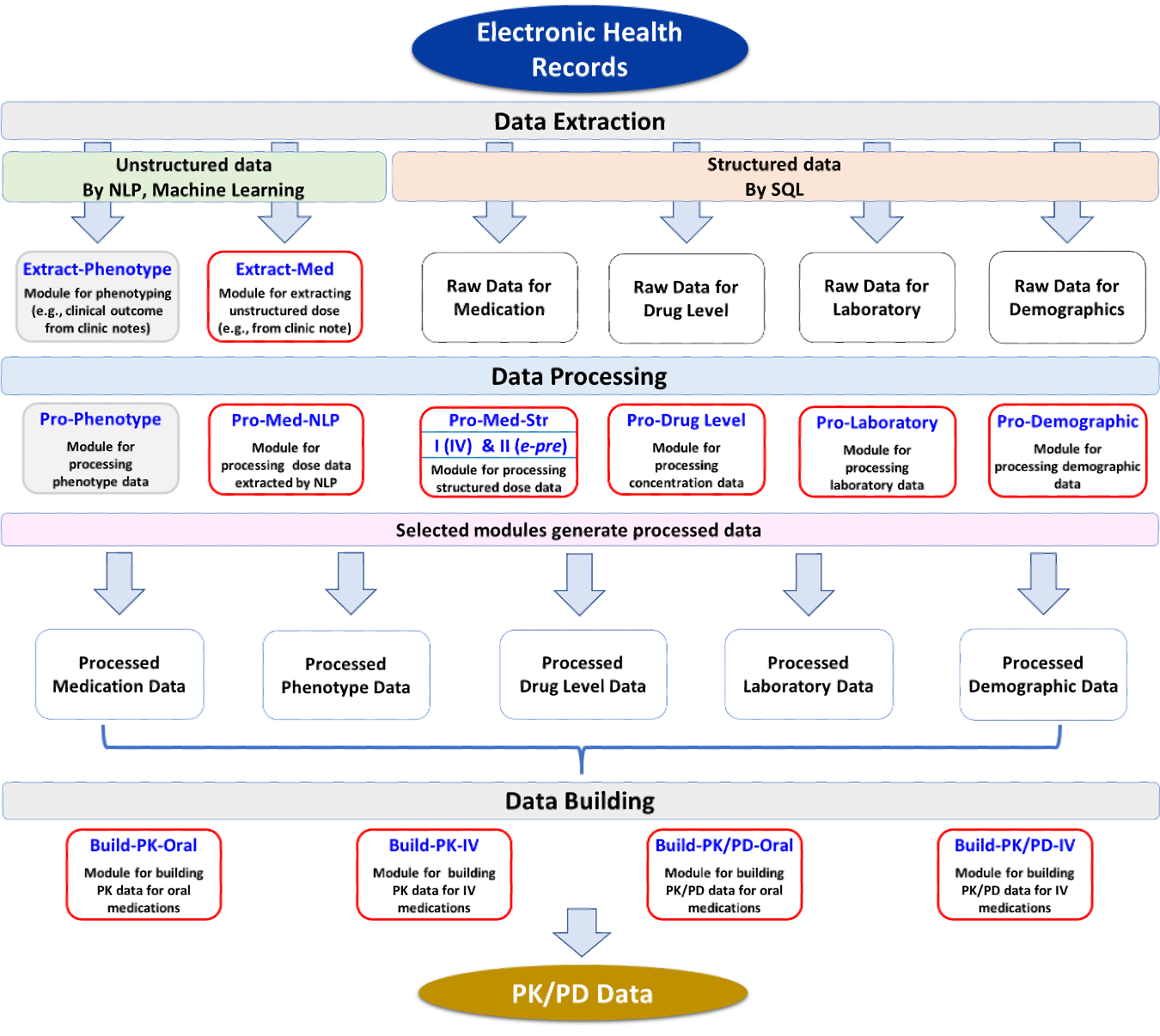
Modified from Clin Pharm Ther 2020.
EHR2PKPD is a modular system, divided into the three major procedures: data extraction (“Extract-”), data processing (“Pro-”), and data building (“Build-”). Modules were created or under development (gray color box) depending on the data element, task to perform, and type of PK/PD models.
For drugs with complex prescription pattern, dose data obtained from e-prescription databases may not be accurate enough to perform PK/PD studies. For these drugs, we may need to extract drug dose information from clinical notes using a natural language processing (NLP) system. We developed a flexible and targeted NLP system that can directly extract drug dose information from clinical notes, which was incorporated into our system (Extract-Med).
Building drug dose data from extracted dose information can be challenging. To address these challenges, we developed a dose data building algorithm that was implemented in our system (Pro-Med-NLP).
For drugs with simple prescription pattern, dose data can be relatively easily extracted from e-prescription databases and processed using Pro-Med-Str module.
Other data elements such as drug levels (Pro-Drug Level), demographics (Pro-Demographic), and laboratory data (Pro-Laboratory) can be processed using our system. These data can be combined with processed dose data to build PK/PD data using PK/PD data building modules (e.g., Build-PK-IV, Build-PK-Oral).
Note:
The NLP system is available as an R package, medExtractR, and the functions to run each module are implemented as an R package, EHR. More details can be found in Choi et al.\(^{1}\), and additional modules will be added in the future as it evolves.
As the R package, EHR, is still in active development, we recommend installing from our GitHub repository with the following command: devtools::install_github(‘choileena/EHR/EHR/’)
Lab Team
| Cole Beck | Marisa Blackman | Elizabeth McNeer | Michael Williams |

|

|

|

|
Lab Alumni
| Hannah L. Weeks | Nathan T. James |

|

|
References
- Choi L, Beck C, McNeer E, Weeks HL, Williams ML, James NT, Niu X, Abou-Khalil BW, Birdwell KA, Roden DM, Stein CM. Development of a System for Post-marketing Population Pharmacokinetic and Pharmacodynamic Studies using Real-World Data from Electronic Health Records. Clinical Pharmacology & Therapeutics. 2020 Apr;107(4):934-43. doi: 10.1002/cpt.1787.